|
|
Problems with performance between SLAC and CERN
Les Cottrell Page created:
December 13, 2001, last update December 13, 2001.
|
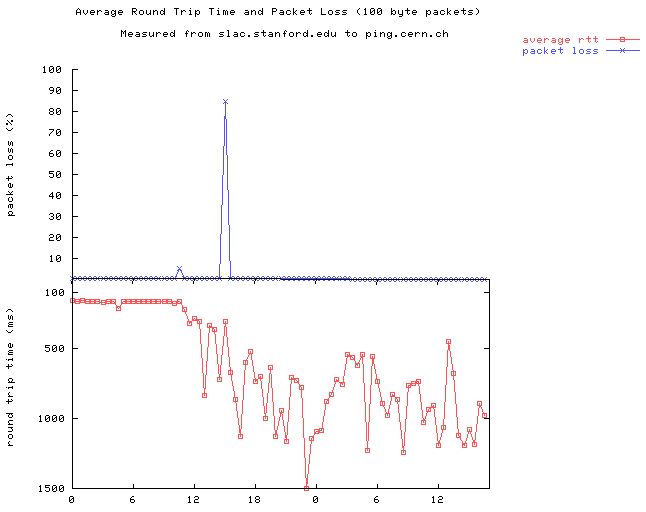 Since around noon 12/12/01 the ping RTTs between SLAC and
CERN increased from about 150msec to 700-1200 msec.
See
the figure to the right, where the PingER data shows the losses in blue, and the round trip
time (RTT) in red, and the onset of the problem is visible around 11am PST.
From pingroutes before and after (see below), it appears the congestion is at
the ESnet to CERN interchange in Chicago. We get a similar
conclusion from pipechar. It is possible that this is related to a large
file transfer from SLAC to IN2P3. I do not know who is doing this yet, if I look at
the biggest host shipping data to the network (using netflow) it appears to be datamove03 and on
that host there are multiple bbftps running from account bbrdist.
The Unix who command says
bbrdist is logged on multiple times from many places, see below.
The bbftp traffic shows up
as heavy traffic at SLAC and on the CERN-IN2P3 link.
The BaBarians
have been making transfers of this size & rate for several months now, but
this kind of poor performance (RTT) has not been observed before. I am wondering
if there is a problem at Chicago.
The problem was reported to ESnet and trouble ticket TTS#8206 was opened at
6:35pm 12/13/01 PST.
Since around noon 12/12/01 the ping RTTs between SLAC and
CERN increased from about 150msec to 700-1200 msec.
See
the figure to the right, where the PingER data shows the losses in blue, and the round trip
time (RTT) in red, and the onset of the problem is visible around 11am PST.
From pingroutes before and after (see below), it appears the congestion is at
the ESnet to CERN interchange in Chicago. We get a similar
conclusion from pipechar. It is possible that this is related to a large
file transfer from SLAC to IN2P3. I do not know who is doing this yet, if I look at
the biggest host shipping data to the network (using netflow) it appears to be datamove03 and on
that host there are multiple bbftps running from account bbrdist.
The Unix who command says
bbrdist is logged on multiple times from many places, see below.
The bbftp traffic shows up
as heavy traffic at SLAC and on the CERN-IN2P3 link.
The BaBarians
have been making transfers of this size & rate for several months now, but
this kind of poor performance (RTT) has not been observed before. I am wondering
if there is a problem at Chicago.
The problem was reported to ESnet and trouble ticket TTS#8206 was opened at
6:35pm 12/13/01 PST.
If indeed it is a baBar bbftp transfer that is achieving high throughput while interactive
throughput is poor, that is very informative, and suggests we may want to try some Quality of Service
(Scavenger Service applied to bbftp so it gets lower priority) at the congestion point.
iepm@pharlap $ /afs/slac/g/scs/bin/fpingroute.pl -c 100 ccasn01.in2p3.fr
Tue Dec 11 11:14:56 2001 Architecture=SUN5, commands=traceroute -q 1 and ccasn01.in2p3.fr
fpingroute.pl version=0.2, 11/29/01. Author cottrell@slac.stanford.edu, debug=1
using traceroute to get nodes in route from pharlap (134.79.240.26) to ccasn01.in2p3.fr starting at node 1
traceroute: Warning: ckecksums disabled
traceroute to ccasn01.in2p3.fr (134.158.105.21), 30 hops max, 40 byte packets
fpingroute.pl version 0.2, 11/29/01 found 11 hops in route from pharlap to ccasn01.in2p3.fr
1 router1.SLAC.Stanford.EDU (w.x.y.z) 0.338 ms
2 router2.SLAC.Stanford.EDU (w.x.y.z) 0.360 ms
3 192.68.191.146 (192.68.191.146) 0.438 ms
4 snv-pos-slac.es.net (134.55.209.1) 1.143 ms
5 chi-s-snv.es.net (134.55.205.102) 59.616 ms
6 ar1-chicago-esnet.cern.ch (198.124.216.73) 49.856 ms
7 cernh9-pos100.cern.ch (192.65.184.34) 157.609 ms
8 in2p3-cernh9.cern.ch (192.65.184.46) 158.547 ms
9 192.70.69.81 (192.70.69.81) 179.420 ms
10 Lyon-ANDA.in2p3.fr (134.158.224.1) 193.656 ms
11 ccasn01.in2p3.fr (134.158.105.21) 188.903 ms
Wrote 11 addresses to /tmp/fpingaddr, now ping each address 100 times from pharlap starting at hop 1 ...
pings/node=100 100 byte packets 1400 byte packets
NODE %loss min max avg %loss min max avg from pharlap
1 router1.SLAC.Stanford.EDU AS3671 0.0% 0.2 0.5 0.2 0.0% 0.3 0.7 0.4 Tue Dec 11 11:14:57 PST 2001
2 router2.SLAC.Stanford.EDU AS3671 0.0% 0.3 0.9 0.4 0.0% 0.7 124.2 2.0 Tue Dec 11 11:14:57 PST 2001
3 192.68.191.146 0.0% 0.5 1.3 0.6 0.0% 1.1 64.3 1.9 Tue Dec 11 11:14:57 PST 2001
4 snv-pos-slac.es.net AS293 0.0% 1.0 84.3 6.8 0.0% 1.8 95.0 11.7 Tue Dec 11 11:14:57 PST 2001
5 chi-s-snv.es.net AS293 0.0% 48.9 174.9 64.0 0.0% 49.7 122.3 60.4 Tue Dec 11 11:14:57 PST 2001
6 ar1-chicago-esnet.cern.ch AS291 0.0% 49.1 250.6 74.8 0.0% 49.9 248.0 54.3 Tue Dec 11 11:14:57 PST 2001
7 cernh9-pos100.cern.ch AS513 0.0% 157.4 359.6 179.7 0.0% 158.5 352.0 165.7 Tue Dec 11 11:14:57 PST 2001
8 in2p3-cernh9.cern.ch AS513 0.0% 158.5 361.7 181.4 0.0% 160.0 205.2 162.4 Tue Dec 11 11:14:57 PST 2001
9 192.70.69.81 AS2200 0.0% 177.6 405.9 200.9 0.0% 179.4 428.2 185.4 Tue Dec 11 11:14:57 PST 2001
10 Lyon-ANDA.in2p3.fr AS789 0.0% 178.1 388.1 201.9 0.0% 180.0 232.4 184.4 Tue Dec 11 11:14:57 PST 2001
11 ccasn01.in2p3.fr AS789 0.0% 177.1 375.6 198.3 0.0% 179.8 193.4 181.5 Tue Dec 11 11:14:57 PST 2001
Tue Dec 11 11:18:23 2001 fpingroute.pl done.
----------------------------------------
iepm@pharlap $ /afs/slac/g/scs/bin/fpingroute.pl -c 100 sunstats.cern.ch
Thu Dec 13 15:52:25 2001 Architecture=SUN5, commands=traceroute -q 1 and sunstats.cern.ch
fpingroute.pl version=0.2, 11/29/01. Author cottrell@slac.stanford.edu, debug=1
using traceroute to get nodes in route from pharlap (134.79.240.26) to sunstats.cern.ch starting at node 1
traceroute: Warning: ckecksums disabled
traceroute to sunstats.cern.ch (192.65.185.20), 30 hops max, 40 byte packets
fpingroute.pl version 0.2, 11/29/01 found 8 hops in route from pharlap to sunstats.cern.ch
1 router1.SLAC.Stanford.EDU (w.x.y.z) 0.396 ms
2 router2.SLAC.Stanford.EDU (w.x.y.z) 0.368 ms
3 192.68.191.146 (192.68.191.146) 0.410 ms
4 snv-pos-slac.es.net (134.55.209.1) 8.588 ms
5 chi-s-snv.es.net (134.55.205.102) 48.707 ms
6 ar1-chicago-esnet.cern.ch (198.124.216.73) 1105.802 ms
7 cernh9-pos100.cern.ch (192.65.184.34) 1376.256 ms
8 sunstats.cern.ch (192.65.185.20) 1218.507 ms
Wrote 8 addresses to /tmp/fpingaddr, now ping each address 100 times from pharlap starting at hop 1 ...
pings/node=100 100 byte packets 1400 byte packets
NODE %loss min max avg %loss min max avg from pharlap
1 router1.SLAC.Stanford.EDU AS3671 0.0% 0.2 0.6 0.3 0.0% 0.3 0.7 0.4 Thu Dec 13 15:52:30 PST 2001
2 router2.SLAC.Stanford.EDU AS3671 0.0% 0.3 83.2 1.2 0.0% 0.7 1.1 0.8 Thu Dec 13 15:52:30 PST 2001
3 192.68.191.146 0.0% 0.5 34.5 1.4 0.0% 1.1 1.7 1.2 Thu Dec 13 15:52:30 PST 2001
4 snv-pos-slac.es.net AS293 0.0% 0.9 132.2 9.2 0.0% 1.8 81.7 10.0 Thu Dec 13 15:52:30 PST 2001
5 chi-s-snv.es.net AS293 0.0% 48.8 222.1 57.7 1.0% 50.4 229.6 77.9 Thu Dec 13 15:52:30 PST 2001
6 ar1-chicago-esnet.cern.ch AS291 1.0% 793.6 1249.4 1031.9 0.0% 417.8 983.5 678.8 Thu Dec 13 15:52:30 PST 2001
7 cernh9-pos100.cern.ch AS513 1.0% 903.6 1236.6 1142.9 1.0% 526.1 1070.3 794.3 Thu Dec 13 15:52:30 PST 2001
8 sunstats.cern.ch AS513 1.0% 907.5 1235.4 1141.0 1.0% 535.9 935.1 787.7 Thu Dec 13 15:52:30 PST 2001
Thu Dec 13 15:56:09 2001 fpingroute.pl done.
Pingroute from IN2P3 to SLAC during problem
ccasn07:tcsh[22] pingroute.pl pharlap.slac.stanford.edu
Fri Dec 14 16:29:14 2001
Architecture=SUNOS, commands=traceroute -q 1 and pharlap.slac.stanford.edu 1400 10
pingroute.pl version=1.7, 1/21/01. Author cottrell@slac.stanford.edu, debug=1
pingroute.pl version 1.7, 1/21/01 using traceroute to get nodes in route from ccasn07 (134.158.105.27) to pharlap.slac.stanford.edu
traceroute to pharlap.slac.stanford.edu (134.79.240.26), 30 hops max, 40 byte packets
pingroute.pl version 1.7, 1/21/01 found 11 hops in route from ccasn07 to pharlap.slac.stanford.edu
1 Lyon-ANDA.in2p3.fr (134.158.104.100) 1.379 ms
2 Lyon-INTER.in2p3.fr (134.158.224.4) 1.563 ms
3 Cern1.in2p3.fr (192.70.69.82) 20.278 ms
4 cernh9-in2p3.cern.ch (192.65.184.45) 141.867 ms
5 ar1-chicago-pos410.cern.ch (192.65.184.33) 268.194 ms
6 cern-chi-atm.es.net (198.124.216.74) 1482.942 ms
7 snv-s-chi.es.net (134.55.205.101) 1527.635 ms
8 slac-pos-snv.es.net (134.55.209.2) 1528.479 ms
9 RTR-DMZ1-VLAN400.SLAC.Stanford.EDU (192.68.191.149) 900.871 ms
10 *
11 PHARLAP.SLAC.Stanford.EDU (134.79.240.26) 1534.507 ms
Wrote 11 addresses to /tmp/pingaddr, now ping each address 10 times from ccasn07 starting at hop 1
pings/node=10 100 byte packets 1400 byte packets
NODE %loss min max avg %loss min max avg from ccasn07
134.158.104.100 LYON-ANDA.IN2P3.FR 0% 1.0 5.0 2.0 0% 0.0 0.0 0.0 Fri Dec 14 16:29:31 MET 2001
134.158.224.4 LYON-INTER.IN2P3.FR 0% 1.0 2.0 1.0 0% 0.0 0.0 0.0 Fri Dec 14 16:29:40 MET 2001
192.70.69.82 CERN1.IN2P3.FR 0% 20.0 20.0 20.0 0% 0.0 0.0 0.0 Fri Dec 14 16:29:49 MET 2001
192.65.184.45 CERNH9-IN2P3.CERN.CH 0% 20.0 21.0 20.0 0% 0.0 0.0 0.0 Fri Dec 14 16:29:58 MET 2001
192.65.184.33 AR1-CHICAGO-POS410.CERN.CH 0% 134.0 134.0 134.0 0% 0.0 0.0 0.0 Fri Dec 14 16:30:07 MET 2001
198.124.216.74 CERN-CHI-ATM.ES.NET 0% 929.0 979.0 944.0 0% 0.0 0.0 0.0 Fri Dec 14 16:30:16 MET 2001
134.55.205.101 SNV-S-CHI.ES.NET 0% 1044.0 1323.0 1213.0 0% 0.0 0.0 0.0 Fri Dec 14 16:30:26 MET 2001
134.55.209.2 SLAC-POS-SNV.ES.NET 0% 1277.0 1283.0 1279.0 0% 0.0 0.0 0.0 Fri Dec 14 16:30:37 MET 2001
192.68.191.149 RTR-DMZ1-VLAN400.SLAC.STANFORD 100% 0.0 0.0 0.0 0% 0.0 0.0 0.0 Fri Dec 14 16:30:47 MET 2001
134.79.240.26 PHARLAP.SLAC.STANFORD.EDU 0% 1257.0 1295.0 1272.0 0% 0.0 0.0 0.0 Fri Dec 14 16:31:06 MET 2001
ccasn07:tcsh[23]
3cottrell@datamove03:~>who objysrv pts/0 Dec 11 16:57 (scs-10.slac.stanford.edu) bbrdist pts/1 Dec 13 10:37 (muse.phys.uvic.ca) bbrdist pts/2 Dec 13 13:56 (epbif1.ph.bham.ac.uk) bbrdist pts/3 Dec 12 02:47 (ccasn01.in2p3.fr) zghiche pts/4 Dec 12 03:13 (cms2.cern.ch) bbrdist pts/5 Dec 13 17:17 (flora06.slac.stanford.edu) bbrdist pts/6 Dec 12 06:48 (epbif1.ph.bham.ac.uk) objysrv pts/7 Dec 12 12:39 (scs-10.slac.stanford.edu) neal pts/8 Dec 12 13:44 (boreas.slac.stanford.edu) neal pts/9 Dec 12 13:48 (boreas.slac.stanford.edu) bbrdist pts/10 Dec 13 02:39 (ccasn01.in2p3.fr) cottrell pts/11 Dec 13 17:28 (pharlap.slac.stanford.edu)
Olivier Martin of CERN responded at 12:15am 12/14/01 PST:
I have nothing against QBSS, however, in this particular case it looks like
the problem only shows up on the ESnet part of the path, in other words even
though the CERN-USA link is loaded 50%, the performance characteristics of
traffic to non-ESnet destnations (i.e. RTT & Throughput) does not seem to be
affected very much, so is there something in ESnet that could explain this
behaviour?
Joe Metzger of ESnet responded 7:40am 12/14/01:
The large flows from SLAC to CERN that started a couple weeks
ago have been causing problems in our Chicago hub. Yesterday
afternoon we implemented the first part of some configuration
changes to stop significant packet loss on some paths through
Chicago. The rest of that change should happen Monday.
The change yesterday effectively moved all of the dropped packets
into queues on a router which is the cause of the large delays.
My thought is that queuing packets is better than dropping. However,
we could shorten the length of this queue which will increase
packet loss but shorten delay as a short term fix.
Currently we are shaping the traffic to CERN at 70 Mbps sustained.
After Mondays changes we will be able to bump that up.
We should talk about trying to setup a scavenger service on
your flows so to reduce the impact on interactive traffic.
I think that will probably be the best long term solution.
Email from cottrell 8:05am 12/14/01:
I believe it will be pretty easy for us to get our BaBarians who use bbftp to use the -q
option to set the TOS/DSCP bits to QBSS. I can also assist with tests using bbcp with the TOS bits set.
I understand your rationale for increasing the queue length. However, I think in this case we
ran into a classic example where overlong queues can be as bad as losses as long as
one application (bbftp) is able to accomodate the long queues with big windows and large
numbers of streams. Thus I would advocate going back to the smaller queues and packet losses which
will degrade the bbftp while allowing the interactive traffic to work better.
I guess then it is a matter of you applying the appropriate QoS factors to the router
where the congestion is occuring. Is the router(s) involved Cisco(s). If so we may be able to assist in
providing the appropriate configuration parameters. I am also ccing Stanislaus Shalunov of I2
since he is heavily involved in QBSS and I am sure will be excited about this.
Email from Joe Metger of ESnet 10:20am 12/14/01 PST
Les,
We have cut down the queue size and are seeing shorter delays as expected.
Ping now identified the RTT as being min/avg/max for 156 pings: 182/245/311 msec.